
Considérations de précision
Cette page couvre les sujets suivants:
- Incohérences dans les cartes de précipitations en raison de différentes résolutions du modèle;
- Précision inférieure avec le modèle brut de la plus haute résolution;
- Faiblesse des modèles de simulation météorologique dans les régions tropicales;
- Autres ensembles de données géographiques disponibles pour la comparaison;
- Faiblesse croissante des ensembles de données d’observation par satellite à mesure qu'on s'éloigne de l'équateur;
- Incohérences dans les séries temporelles fusionnées de différents modèles;
- Aperçu des vastes études de vérification à long terme;
Les simulations d'événements et de quantités de précipitatioms, ainsi que les quantités de précipitation réelles, comptent parmi les variables les plus importantes en météorologie. Elles montrent simultanément une fréquence extrêmement variable sur de petites distances, en raison de leur nature physique complexe, et sont donc parmi les variables les plus difficiles à simuler à haute précision.
Alors que nous travaillons continuellement à l'amélioration de nos simulations, nous souhaitons avec cette page informer nos utilisateurs des problèmes de précision les plus importants liés aux prévisions de précipitation, afin de pouvoir interpréter correctement les données et les carences potentielles.
En général, il est important de faire la distinction entre la précision des quantités de précipitation et la précision des événements de précipitation, avec des résultats parfois divergents. Lorsque vous mesurez les mesures de précision, pensez d'abord à vos priorités: un événement de précipitation est-il le critère le plus important (c.-à-d. est-il important que demain soit totalement sec ou s'il pleut un peu) ou la quantité de précipitations (c.-à-d. qu'il importe de savoir s'il pleut 10 ou 30 mm dans les 2 prochains jours).
Incohérences des cartes de précipitation en raison de différentes résolutions du modèle
Les cartes météo de meteoblue sélectionnent automatiquement les données du modèle le plus approprié, qui change en fonction de la zone d’affichage de la carte et du niveau de zoom (par exemple, pour l’Europe centrale, le niveau de zoom 4 indique les données NEMSGLOBAL, le niveau de zoom 5 indique les données NEMS12 et le niveau de zoom 6 indique les données NEMS4).
En ce qui concerne les précipitations, cela a pour conséquence que les cartes de basse résolution semblent montrer une distribution spatiale plus étendue des précipitations que les cartes à haute résolution. Inversement, alors que les cartes à haute résolution montrent une distribution spatiale de précipitation plus étroite, elles indiquent des quantités de précipitation locales plus élevées.
Ceci s’explique facilement: si une cellule de la grille avec une résolution de 30x30 km est composée de 3x3 cellules avec une résolution de 10x10 km, et si l’une de ces cellules plus petites a simulé un orage, la totalité de la cellule de 30x30 km de la vue basse résolution montrera un orage et sera peinte en bleu (= précipitations présentes), car elle ne peut pas distinguer dans quelle partie de la cellule de la grille l'orage se produit: le modèle à basse résolution sait juste que des précipitations se produiront quelque part dans la grande cellule en grille. Et simultanément, cela donnera la moyenne de la quantité de précipitations de cet événement local sur toute la cellule de la grille, ce qui réduira l'intensité.
Précision inférieure avec le modèle brut de la plus haute résolution
Nos études de vérification ont montré que la précision des simulations de précipitations à partir du modèle à résolution la plus élevée (4 km en Europe) est en moyenne inférieure à celle des modèles à résolution plus faible (12 à 30 km), en raison de la présence à petite échelle d'événements de précipitations.
Ceci peut être facilement compris en imaginant un petit orage qui avance sur une piste qui est en réalité compensée par 2 km de la piste simulée (ce qui peut facilement se produire). Maintenant, avec une cellule de grille de 4 km, il est probable que la piste réelle traverse des cellules de grille différentes de celle de la piste simulée. En conséquence, la simulation produira deux pistes de cellules de grille incorrectes (une où l’orage a été simulé mais n'est pas passé et une où aucun orage n’a été simulé mais a bien eu lieu) en raison d’un seul orage. Le fait d’adopter un modèle de résolution inférieure réduit ce problème, car le décalage entre les pistes simulées et réelles doit être beaucoup plus important pour avoir la même probabilité de prédire deux pistes de cellules en grille erronées en même temps.
Les résultats bruts les plus précis du modèle sont obtenus avec une résolution spatiale de 6-12 km. La simulation à 12 km s'est avérée plus précise que la simulation à 30 km. Des exceptions à ce résultat se trouvent dans les zones montagneuses, où les modèles à haute résolution produisent une meilleure précision des précipitations que les modèles à basse résolution, car les premiers ont une meilleure compréhension de la topographie.
Lorsque vous utilisez les données meteoblue, vous recevrez la sortie du modèle suivante:
- Dans l'interface history+ (si les données de précipitation de haute résolution sont sélectionnées), ainsi que dans le history+ API (si aucun domaine n'est sélectionné), et non le plus élevé, le modèle de moyenne résolution (12 km pour l'Europe) est extrait automatiquement au lieu du modèle de plus haute résolution (4 km pour l'Europe). Vous avez le choix de sélectionner le modèle de basse résolution pour les données à long terme.
- Pour les données demandées spécifiquement à partir d'un modèle spécifique, vous recevrez ces données de modèle. Certaines lacunes dans les données peuvent être comblées avec des données du modèle à résolution inférieure. Ces écarts peuvent être indiqués sur demande.
Les prévisions (pour l'API: quand aucun domaine n'est spécifié) ne différencient pas les modèles, car les données fournies sont une composition du multimodèle, auquel aucune résolution spécifique ne peut être attribuée; cette question ne s'applique donc pas. Cependant, les séries de données historiques ne pourront pas reproduire exactement la prévision multimodèle, car la disponibilité des modèles au moment de la production de prévision ne peut pas être reproduite exactement après coup. Si une vérification des prévisions de précipitations historiques est nécessaire, les prévisions de précipitations réelles doivent être stockées au moins une fois par jour.
Faiblesse des modèles de simulation météorologique dans les régions tropicales
Dans les régions tropicales (ainsi que dans les régions de fortes pluies de mousson), la simulation de précipitation est particulièrement difficile. Cela est dû à la fréquence élevée des précipitations, avec de grandes quantités de pluie en peu de temps. De plus, les précipitations convectives et les tempêtes orageuses sont plus courantes. Ces deux formes de précipitation peuvent être très complexes et localement très incohérentes, et sont donc encore plus difficiles à simuler avec précision, par rapport à d'autres formes de précipitation.
L’implication de cette difficulté dans une simulation précise est que la quantité de précipitation dans les régions tropicales est généralement nettement sous-estimée (des exceptions s’appliquent, ce qui rend très difficile une correction systématique).
Autres ensembles de données géographiques disponibles pour la comparaison
Afin de résoudre ces problèmes de précision avec les simulations de précipitations, meteoblue collecte et distribue, en plus de nos propres modèles, une large gamme d'ensembles de données de précipitations provenant d’opérateurs tiers.
Outre un grand nombre de modèles globaux (2 modèles) et régionaux (14 modèles), la base de données de meteoblue contient également des modèles de prévision tels que GFS (NOAA) et ICON (DWD), des modèles de réanalyse tels que ERA5 (ECMWF), des ensembles de données d'observation satellite comme CHIRPS2 et CMORPH, elles sont encore améliorées par des corrections avec des mesures de précipitations, ainsi que par des données de radar dans certaines régions (pour diverses raisons, aucune donnée radar complète ne peut être proposée pour le monde entier). Comme tous ces ensembles de données ont des points forts et des imprécisions différentes, il peut exister de grandes différences de précision en fonction du moment et du lieu de l'enquête. Plus d'informations sont disponibles sur nos pages de vérification.
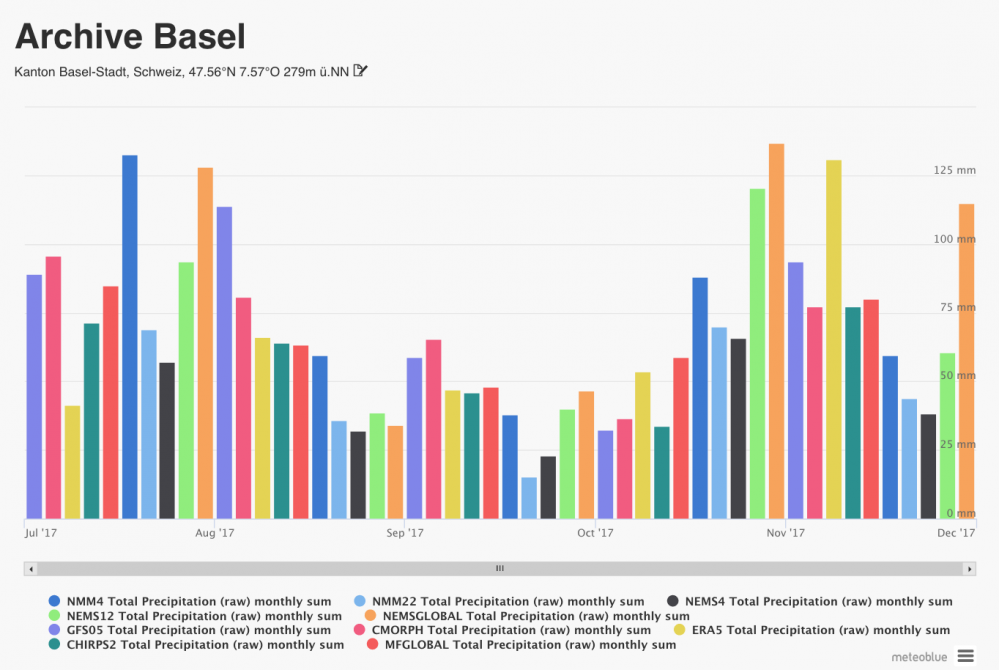
Diverses ensembles de données de précipitations disponibles de la base de données meteoblue
En conclusion, il n'est pas possible de définir facilement un jeu de données pour obtenir la meilleure précision possible pour toutes les utilisations et tous les lieux. De plus, sans mesure de haute qualité à une distance raisonnable, il est difficile d'estimer quel ensemble de données a la meilleure qualité dans cette situation. Pour plus d'informations sur la qualité des différents jeux de données, veuillez consulter notre page de vérification des précipitations.
Avec les APIs de history et prévision de meteoblue, en définissant l'attribut de domaine sur le modèle souhaité, des données de simulation de précipitation spécifiques peuvent être collectées.
Avec l'API de précipitations historiques, tous les ensembles de données mentionnés ci-dessus peuvent être délivrés selon les besoins spécifiques des clients en ce qui concerne les précipitations.
Pour history+, nous publierons une version étendue cette année, qui rend tous les différents ensembles de données de précipitation disponibles via l'interface populaire.
Faiblesse croissante des ensembles de données d'observation de satellite avec l'éloignement de l'équateur
Les ensembles de données CHIRPS2 et CMORPH sont produits par des satellites géosynchrones placés au-dessus de l'équateur, parcourant la Terre à la même vitesse que la rotation de la Terre. Par conséquent, leur vue sur les zones équatoriales est précise et rectangulaire, tandis que sous les latitudes les plus élevées, la vue de satellite doit traverser des couches plus atmosphériques, sous un angle plus petit. Par conséquent, la qualité est meilleure dans les zones équatoriales et diminue progressivement vers les pôles.
CHIRPS2 est uniquement disponible pour les régions comprises entre 50 ° S et 50 ° N et CMORPH uniquement entre 70 ° S et 70 ° N. Toutefois, il est suggéré que ces ensembles de données soient utilisés de manière encore plus restrictive, à partir de 45 ° S à 45 ° N ou même entre 30 ° et 30 ° S N seulement. Grâce à nos plus récentes études de vérification, on peut voir que pour des endroits plus éloignés de l'équateur, d'autres ensembles de données de précipitations montrent la plus grande précision.
Incohérences dans les séries temporelles fusionnées de différents modèles
Comme la nature incohérente de précipitation ne permet pas une correction de biais significative (tout comme le post-traitement MOS ne fournit pas non plus d'améliorations), comme cela peut être fait automatiquement pour d'autres variables, la fusion de différents modèles et séries chronologiques n'est pas possible sans laisser d'importantes incohérences dans les données.
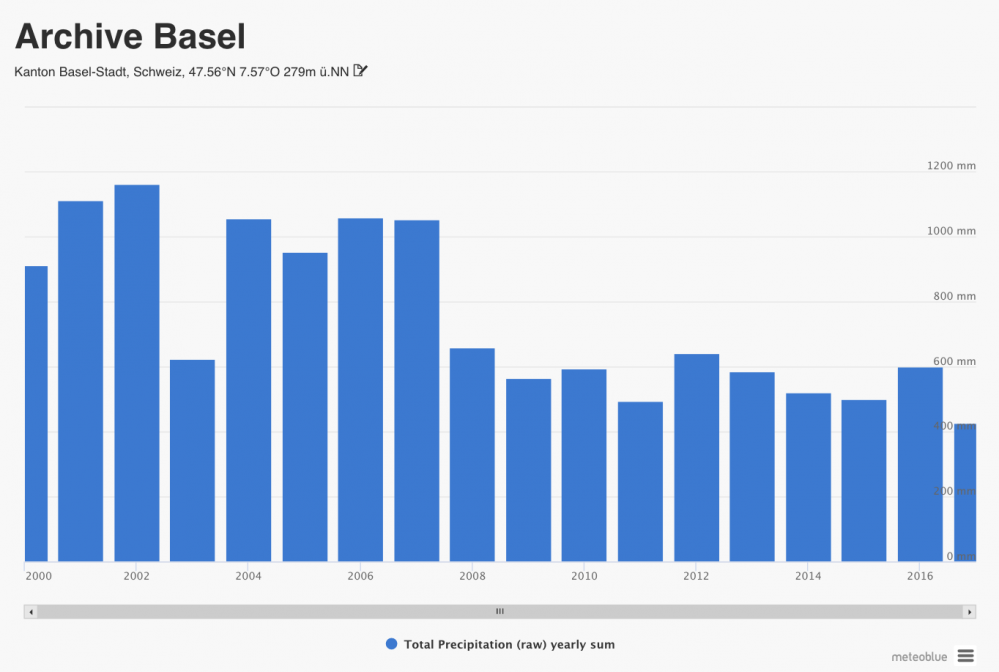
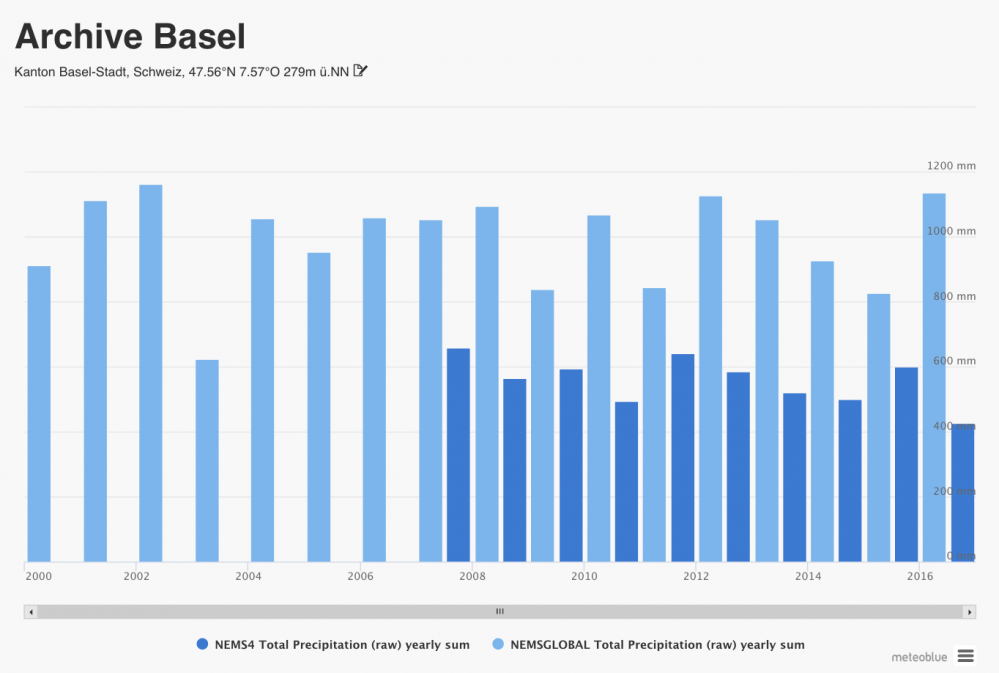
Ceci est important à prendre en compte lors de la collecte de longues séries de données de précipitations à partir de history API de meteoblue. Lorsqu'aucun domaine (ou un domaine local) n'est spécifié (ce qui est suggéré en général et pour la plupart des autres variables), l'API fournit des données de haute résolution, à commencer par la mise en œuvre du modèle actuel de la plus haute résolution. Lorsque des données de dates antérieures sont demandées, l'API fournit des données de basse résolution du modèle NEMSGLOBAL (remontant à 1984). Afin d'éviter cette incohérence, nous suggérons d'utiliser une API de précipitation historique spécifique, en plus de l'API d'historique normale, qui reste la plus appropriée pour toutes les autres variables..
Dans l'interface history+, il est important que l'ensemble de données de précipitation correct («haute résolution, gamme de temps limitée» ou «basse résolution, depuis 1984») soit demandé, en fonction des exigences spécifiques d'utilisation. Notez que lorsque, pour un lieu spécifique, il n'existe aucun modèle local, la «gamme de résolution élevée et limitée» fournit quand même le modèle global à basse résolution. La résolution disponible localement peut être facilement confirmée en regardant la taille de cellule de la grille du rainSPOT.
Les données de prévision résultent d'une composition de multimodèle, auquel aucune résolution spécifique ne peut être attribuée. Ce problème ne s'applique donc pas.
Aperçu de vastes études de vérification à long terme
meteoblue mène de nombreuses études de vérification à long terme afin de comprendre la qualité des données de précipitation, produites par ses propres modèles ainsi que par divers opérateurs tiers, comparées à plusieurs milliers de stations de mesure de précipitation.
D'une manière générale, une bonne simulation de précipitations permet d'estimer correctement 85% des heures sèches/pluvieuses, avec un score de compétence de Heidke compris entre 0,3 et 0,6 pour des événements supérieurs à 1 mm/jour. En ce qui concerne les quantités de précipitations, 90% des données de simulation ont une précision de +/- 30% par rapport aux mesures.
Les méthodes de post-traitement, telles que le mélange de multimodèles ou MLM, permettent d’améliorer la précision de la simulation des précipitations.
Pour plus d'informations et les derniers rapports de vérification, consultez notre page de vérification des précipitations.

