Data sources
In order to describe the weather situation at a given place appropriately, various data sources are needed.
The data used by meteoblue originates from various national weather services as well as further sources. Initial conditions are usually determined through the help of measurements and observations, which cover the most important locations and weather variables, but describe only a fraction of the surface of the Earth and weather processes. These measurements are then incorporated into model simulations (data assimilation), to determine the state of the weather over the entire globe. After the model run, the output data may be validated and corrected through measurements and observational data, using different post-processing techniques like downscaling, statistics, machine learning and nowcasting.
To achieve the highest accuracy level it is necessary to combine these different data sources in an intelligent way, which is a key value proposition offered by meteoblue. The offer is complemented with additional geographical information like location names, population density, vegetation health and soil characteristics, which makes meteoblue a unique offer for private and professional applications.
The main data sources are:
- Weather simulation data - These are
data obtained by numerical weather models or reanalysis:
- meteoblue models - available for history & forecast
- Third party models - available for history & forecast
- Reanalysis datasets - available for history only
- Observations - These are records obtained by
manual or mechanical sensing and transformed into weather variables:
- Satellite images - available for nowcast only
- Radiation / Clouds - available for history & nowcast
- Precipitation - available for history & nowcast
- Vegetation - available for history only
- User observations
- Measurements - These are data obtained by
instruments that measure weather variables:
- Temperature - available for history & nowcast
- Precipitation - available for history only
- Wind - available for history & nowcast
- Radiation - available for history only
- Post-processing - These are technical
approaches to combine simulations with measurements and observations:
- Nowcasting - real time correction of forecast
- Statistics (MOS) - statistical downscaling on measurements
- meteoblue Learning MultiModel (mLM) - artificial intelligence that finds the best weather model
- Geographical data - These are location
attributes which are static (for a certain point in time)
- Location names - More than 8 million place names available
- Population density - worldwide population distribution
- Topography - digital elevation model in high resolution
- Land use - worldwide land usage distribution
- Soil characteristics - worldwide soil properties
- Air quality - available for history & forecast
- Ocean models - available for history & forecast
You can find further details about each data source by clicking on the link to the respective page.
Characteristics of the weather data from various sources
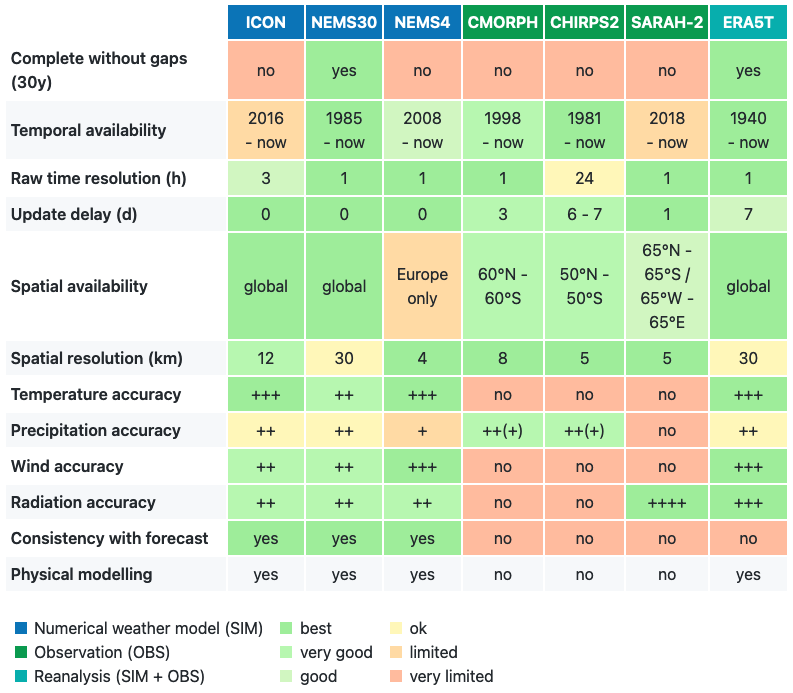
Generally, meteoblue per default offers the dataset with the highest accuracy (for data available through the meteoblue website, API or history+). Nevertheless, for some professional purposes, the right choice of weather data is crucial for the success of the project. To make an adequate choice, a lot of different aspects must be taken into account.
For time series of more than 10 years, the only consistent data series available that include all basic variables are NEMSGLOBAL and ERA5. Both models have the same spatial (30 km) and temporal (1 h) resolution. ERA5 data have the advantage of being recalculated with local measurements. However, this does not grant a generally higher accuracy, especially in places where no measuring stations are available. Also, ERA5 data are only updated irregularly and usually with a delay of several months, whereas NEMSGLOBAL produces seamless datasets from 1984 until 7 days into the future, for every point on Earth. Model choice depends on use criteria. Generally, it is recommended to have a look at both models, in order to derive an estimate of the uncertainty from the differences between the two models.
For precipitation data specifically, the precipitation observational datasets CMORPH and CHIRPS2 are available, also for long time series.
For the last 1 - 5 years, many more weather models are available, some of which with a higher spatial resolution. Generally, as many models as possible should be looked at to get a better understanding of the uncertainty. If local measurements are available, some models might, however, be discarded due to their performance compared to measurements. The best model or model combination has to be evaluated on a case-by-case basis. Some general points:
- Higher resolution does NOT mean higher accuracy neccessarily. It mainly means more spatial detail. This is especially true for precipitation accuracy, which might decline at higher resolution (below 5 km)
- The use of more than one model and making comparisons is beneficial
- Extreme events - like wind storms, thunderstorms, very high winds - are highly unpredictable and will not be accurately reproduced in any numerical weather predicion model or reanalysis data
- Local microclimatic details - like warmer climate on a south facing slope - cannot be reproduced.
- At a specific location, spatial and temporal aggregations are more accurate than hourly data.
An overview of advantages and limitations of the various weather data sources is given in the table below:
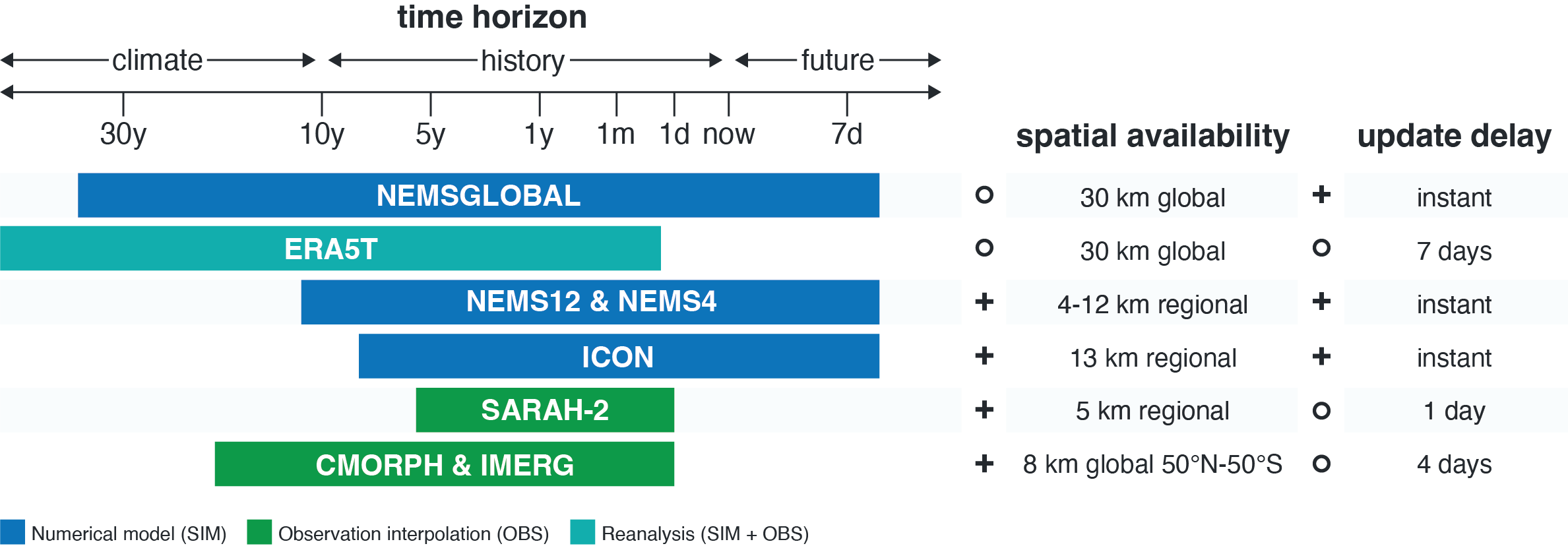
Weather data availability
As stated above, the data sources have different temporal and spacial availabilities. For the availability, we can differentiate three different dimensions:
- Temporal availability (available time range and time resolution)
- Spatial availability (resolution and available region)
- Update frequency (automated updates and delay)
Best model availability is offered from NEMSGLOBAL, which is available for all time ranges since 1984 and updated automatically every day. This means it is available since 01.01.1984 until 7 days ahead. ERA5T is available from 1940 until today with an update delay of 7 days. Other weather data sources are available differently for some years backwards to seven days in the future. Please note that observational data are raw data from third party providers or official networks. Thus, they can show substantial data gaps. The figure below gives an overview for the most important data sources: